Hidden champion "Preprocessing"
Für Datenanalysen gibt es viele Tools. Teils mit langer Historie, teils erst seit kurzem, mit unterschiedlichen Preismodellen und – was sehr wichtig ist – mit ganz unterschiedlicher Spezialisierung. Wie für alle Software-Lösungen gilt: umso weniger speziell einsetzbar ein Tool ist, umso einfacher die Entwicklung und umso allgemeiner dessen Anwendung, aber auch umso mehr Konkurrenz gibt es.
Was die meisten Tools können ist Daten in verschiedenen Diagramm-Typen ansprechend präsentieren, mehr oder weniger komplexe (meist statistische) Auswertungen durchführen und Abfragen ("Queries") zulassen. Gerade für Diagramme gibt es mittlerweile tolle OpenSource-Projekte wie ChartJS, D3 oder Grafana.
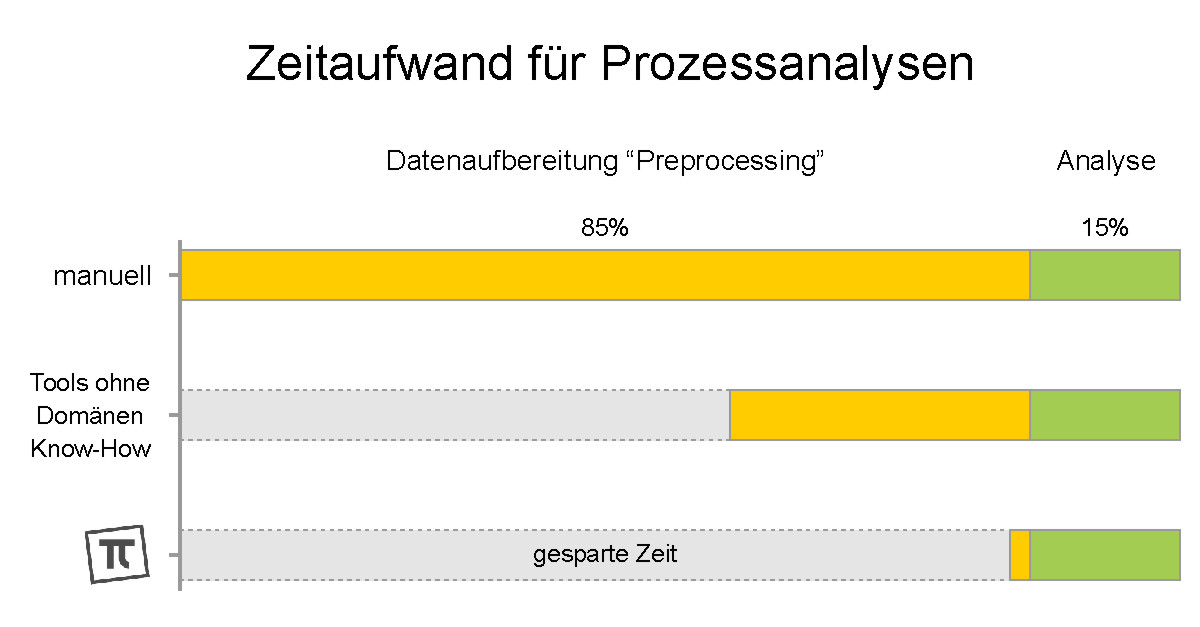
Bei technischen Prozessen ist das alles auch wichtig. Entscheidend ist hier aber das sogenannte "Preprocessing", also das was nötig ist, bevor die eigentliche Analyse startet. Und das können viele Tools nur bedingt, weil oft Domänen Know-How bzw. spezielles Wissen über den Prozess fehlt. Preprocessing macht allerdings 80% und mehr der insgesamt erforderlichen Abeitszeit aus, stellt also einen wichtigen Erfolgsfaktor dar:
PIs Daten kommen in den allermeisten Fällen aus Dateien, die in irgendwelchen Automatisierungsumgebungen rund um den ganzen Erdball generiert wurden. Entsprechend vielfältig sind die Dateien, Datumsformate und Zeitzonen, Ländercodes, physikalischen Einheiten und verwendeten Abkürzungen. Und entsprechend spezialisiert ist PIs Preprocessing. Hier eine ganz persönliche Checkliste aus unserer täglichen Arbeit:
Preprocessing-Checkliste Neue Daten auf mögliche Datumsformate ("YYYY-MM-DD hh:mm:ss" usw.) überprüfen, ggf. neue Datumsformate hinzufügen Neue Daten auf Art und Einhaltung des Zeit-Intervalls (Stunden, Minuten usw.) prüfen und ggf. beim Einlesen korrigieren Neue Daten auf den Zeit-Intervall-Offset prüfen (Sekunden-Abstand zur vollen Stunde) Neue Daten auf Sommer-/Winterzeit prüfen und ggf. beim Einlesen korrigieren Zeitzone berücksichtigen, Unix-Zeitstempel generieren Neue Daten auf Dopplungen und Wiederholungen prüfen und Korrektur-Möglichkeiten anbieten Neue Daten auf bereits vorhandene Daten prüfen und ggf. an bereits vorhandene Daten "anhängen" Neue Daten auf neue oder geänderte Meta-Daten prüfen (Einheit, Text) und ggf. übernehmen Neue Daten (Zahlenwerte) bereinigen: keine ungültigen Werte, Genauigkeit anpassen Berechnungen mit neuen Daten durchführen, Ergebnisse in vordefinierten Diagrammen bereitstellenEin richtig gutes Preprocessing ist aufwendig (und auch sehr aufwendig zu programmieren), oft wahnsinnig spannend, in der eigentlichen Analyse-Phase aber schon wieder uninteressant. Wer redet dann noch über Preprocessing? Deshalb unser "Hidden Champion"
 Dr.-Ing. Martin
Horeni, 01/2022
Dr.-Ing. Martin
Horeni, 01/2022